
Test-driven development (a.k.a. TDD) was rediscovered by Kent Beck and explained in his famous book in 2002. In 2014, David Heinemeier Hansson (the creator of Ruby on Rails) said that TDD is dead and only harms architecture. Robert Martin (the inventor of the SOLID principles) disagreed and explained that TDD may not work only in certain cases. A few days later, he even compared the importance of TDD with the importance of hand-washing for medicine, and added that “it would not surprise me if, one day, TDD had the force of law behind it.” Two years later, now just a few months ago, he wrote more about it, and more, and more. This subject seems to be hot. Of course, I have my own take on it; let me share.
In theory, TDD means “writing tests first and code next.” In practice, according to my experience while working with more than 250 developers over the last four years, it means writing tests when we’re in a good mood and have nothing else to do. And this is only logical, if we understand TDD literally, by the book.
Writing a test for a class without having that class in front of you is difficult. I would even say impossible, if we are talking about real code, not calculator examples. It’s also very inefficient, because tests by definition are much more rigid than the code they validate—creating them first will cause many re-do cycles until the design is stabilized.
I’ve personally written almost 300,000 lines of code in Java, Ruby, PHP, and JavaScript over the last four years, and I have never done TDD by the book: “write a test, make it run, make it right.” Ever.
Code, Deploy, Break, Test, Fix
Even though I’m a huge fan of automated testing (unit or integration) and totally agree with Uncle Bob: Those who don’t write tests must be put in jail, I just have my own interpretation of TDD. This is how it looks:
First, I write code without any tests. A lot of code. I implement the functionality and create the design. Dozens of classes. Of course, the build is automated, the deployment pipeline is configured, and I can test the product myself in a sandbox. I make sure “it works on my machine.”
Then, I deploy it to production. Yes, it goes to my “users” without any tests because it works for me. They are either real users if it’s something open source or one of my pet projects, or manual testers if it’s a money project.
Then, they break it. They either test it or they use it; it doesn’t matter. They just find problems and report bugs. As many as they can.
Right after some bugs are reported, I pick the most critical of them and…voilà!…I create an automated test. The bug is a message to me that my tests are weak; I have to fix them first. A new test will prove that the code is broken. Or maybe I fix an existing one. This is where I go “tests first.” I don’t touch the production code until I manage to break my build and prove the problem’s existence with a new test. Then, I do
git commit.Finally, it’s time to fix the problem. I make changes to the production code in order to make sure the build is green again. Then, I do
git commitandgit push.And I go back to the “deploy” step; the updated product goes to my users.
Once in a while, I have to make serious modifications to the product, like to introduce a new feature or perform a massive refactoring. In this case, I go back to the first step and do it without tests.
The Reasoning Behind
The justification behind this no-tests-upfront approach is simple: We don’t need to test until it’s broken, mostly because we understand that it’s technically not possible to test everything or to fix all bugs. We have to fix only what’s visible and intolerable by the business. If the business doesn’t care or our users/testers don’t see our bugs—we must not waste project resources on fixing them.
On the other hand, when the business or our users/testers are complaining, we have to be very strict with ourselves; our testing system is weak and must be fixed first. We can’t just fix the production code and deploy, because in this case, we may make this mistake again after some refactoring, and our tests won’t catch it. The user will find the bug again, and the business will pay us again to fix it. That will be the waste of resources.
As you can see, it’s all money-driven. First, don’t fix anything if nobody pays for it. Second, fix it once and for all if they actually paid. It’s as simple as that.
The Dynamics
Thanks to this test-and-fix-only-when-broken approach, the balance between production code and test code is not the same over the entire project lifecycle. When the project starts, there are almost no tests. Then, the number of tests grows together with the number of bugs. Eventually, the situation stabilizes, and we can move the product from beta version to the first release.
I created a simple command line tool in order to demonstrate the statistics from a few projects of mine, to prove my point. Take a look at these graphs:
yegor256/takes (Web framework, Java):
yegor256/xembly (XML builder, Java):
jcabi/jcabi-aspects (AOP library, Java):
yegor256/s3auth (S3 gateway, Java):
First commercial project:
Second commercial project:
In each graph, there are two parts. The first one on the top demonstrates the dynamics of production Hits-of-Code (green line), test-related HoC (red line), and the number of issues reported to GitHub (orange line).
The bottom part shows how big the test-related HoC portion is relative to all project activity. In other words, it shows how much effort the project invested into automated tests, compared with the total effort.
This is what I want you to pay attention to: The shape of the curve is almost the same in every project. It looks very similar to a learning curve, where we start to learn fast and then slow down over time: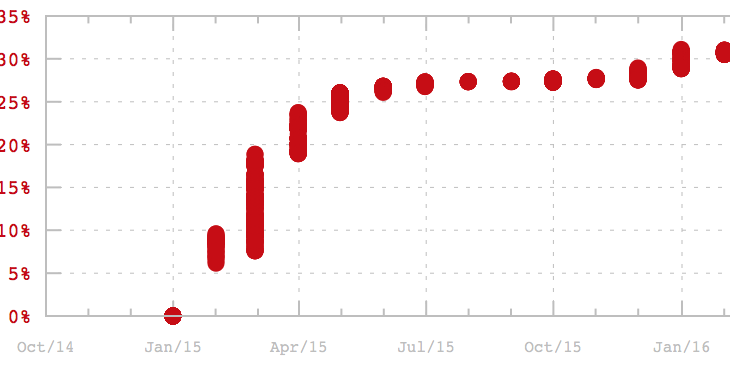
This perfectly illustrates what I just described above. I don’t need tests at the beginning of the project; I create them later when my users express the need for them by reporting bugs. This dynamic looks only logical to me.
You can also analyze your project using my tool and see the graph. It would be interesting to learn what kind of curve you will get.
When do you write unit tests? #testing
— Yegor Bugayenko (@yegor256) February 10, 2019
