Спрашивается, можем ли мы достоверно утверждать, что именно происходило, скажем, шесть веков назад, когда ни Instagram ни даже книгопечатания еще не существовало? Достоверно не можем. Можем лишь предполагать, какие события могли произойти, опираясь на имеющиеся в нашем распоряжении артефакты и учитывая возможность их фальсификации. Чем артефактов меньше и чем они старше, тем больше возможностей совершить ошибку. А ошибки совершаются, и часто.
Например, до недавнего времени считалось, что Иван Грозный убил своего сына, ударив тяжелым царским посохом по голове. Откуда нам это было известно? Через пять лет после якобы убийства, Антонио Поссевино, папский легат и секретарь ордена иезуитов, опубликовал трактат “Московия”, в котором и описал события, о которых якобы имел точные сведения. Затем, через тридцать лет, когда у власти уже была династия Романовых, эту версию повторили, например, в “Хронографе” 1617 года. Еще через двести лет, Карамзин Николай Михайлович в своей “Истории Государства Российского” пересказал версию легата, а еще через полвека Иван Репин написал свою известную картину. Однако, в 1963 году, гробница царя и его семьи была вскрыта и очевидных признаков убийства обнаружено не было: в волосах царевича не было крови. Более того, были обнаружены признаки отравления, но не сына, а всей семьи. Таким образом, версия об убийстве, в которую верил весь мир более четырех веков, оказалсь лишь выдумкой итальянца закрепленной Карамзиным.
Однако, не стоит поспешно обвинять Карамзина. Попытайтесь поставить себя на его место. Ведь если взглянуть на ситуацию с его точки зрения: какой-то Иван Грозный, два с половиной века назад, убил кого-то, или нет — разве это имеет принципиальное значение? Задача была поставлена, заказчик ждал выполнения, а зарплата была внушительной. Так почему бы не написать, что убийство имело место, особенно если есть “первоисточник”, на который можно опереться? Пусть потомки рассудят, если им это будет важно: они могут провести эксгумацию, сопоставить факты, написать диссертации. “По крайней мере, я никого не убивал”, — так, вероятно, размышлял Николай Михайлович, задумываясь о том, соответствует ли истине рассказ того итальянца, о правдивости которого он не имел представления.
А если бы Карамзин пожелал докопаться до истины, не обращая внимания на возможную потерю гонорара, какие бы методы и инструменты он мог использовать? Каковы доступные историкам средства для выявления правды? Ещё более важный вопрос касается точности каждого из этих инструментов: какова их погрешность? Можно предположить, что арсенал методов у историков похож на тот, что используют криминалисты: на основе косвенных и прямых доказательств необходимо воссоздать образ событий, стараясь обеспечить согласованность улик. Также стоит принимать в расчёт показания свидетелей, при этом учитывая степень их заинтересованности в определённой интерпретации событий.
После завершения работы криминалистов следователь объединяет все собранные улики, реконструирует картину произошедшего и направляет материалы в суд, где обе стороны получают возможность высказаться. С одной стороны, адвокаты ищут неточности в собранных данных, стараясь убедить суд в том, что предложенная реконструкция событий неверна — например, что Иван Грозный не убивал своего сына. С другой стороны, прокурор усиливает доводы в пользу правдоподобности своей версии событий. В итоге суд формирует своё, субъективное мнение о случившемся и выносит вердикт. Этот процесс является частью судебного права, представляющего собой механизм установления истины в правовом государстве. Наличие доступной всем гражданам судебной системы — несомненный признак развитого общества. К этой мысли мы ещё вернёмся через минуту.
Пока же, от времен Ивана IV перейдем к ещё более древним эпохам и к событию, предположительно, случившемуся двумя столетиями ранее: грандиозному сражению 8-го сентября 1380-го года между народным ополчением Дмитрия Донского и ордынским войском хана Мамая, с огромным количеством жертв, сыгравшему поворотную роль в русской истории, и позднее названному Куликовской битвой. Несмотря на то, что сам факт массового кровопролития не вызывает сомнений среди историков, убедительно доказать, где именно это произошло, до сих пор проблематично.
Действительно, как можно восстановить координаты поля, на котором случилась кровавая сеча шесть веков тому назад? Где оно, поле это? Наверное, можно снова попытаться опереться на воспоминания “итальянцев-очевидцев”, но в то время не было ни атласов автомобильных дорог, ни Google Maps, да и параллели с меридианами еще не придумали. Даже если у битвы были очевидцы владеющие письмом, могли бы они описать координаты места так, чтобы сегодня их можно было бы найти на Яндекс Картах?

Умением письма кое-кто тогда как раз владел. Некто Софоний Рязанец. Он написал книгу Задонщина, как считается, еще при жизни Дмитрия, в которой рассказал о месте встречи православного князя с татарским темником следующее: “проли́тсѧ крóви наречьке напрѧде” где-то “между дóном и́ непрóм” (на фото Ундольский список, страница 185, выделение мое). Считается, что Софоний — наиболее достоверный свидетель тех событий, а значит нужно искать на карте упомяную речку, где-то рядом будет и поле. Вот только карты Руси XIV века с названиями мелких рек у нас нет.
А если бы такая карта была, я бы искал речку “Напряду”, где-то между Доном и Днепром. Однако, в переводе почему-то эта фраза звучит так: “пролится крови на речьке Непрядве!”. Как именно историки из “напрѧда” сделали “Непрядва”, мне сложно судить. Очевидно, что такой перевод вносит некоторую погрешность в ход дальнейшего расследования по нахождению места проведения битвы. Однако, это лингвистическое допущение ничуть не смутило Степана Нечаева, который в 1848 году обнаружил речку Непрядву на землях своего имения, предложил называть одно из своих полей Куликовым, и стал собирать средства на памятник. Ему наверняка позавидовал, например, владелец речки Навля (Брянская область), тоже подходящей названием под древнюю летопись, но инициатива уже была перехвачена.
Почти полтора века эта версия многих устраивала, до тех пор пока уже в наше время математик Анатолий Фоменко с коллегами, в рамках работы над Новой Хрологией, не предложили перенести Куликово поле в центр нынешней Москвы, аргументируя это в основном 1) большей целесообразностью, с военной точки зрения, такого расположения в те времена, 2) почти полной бесплодностью раскопков в имении Нечаева, 3) множественными захоронениями погибших воинов, обнаруженными на территории Сретенки (район Москвы) и 4) обнаружением практически всех географических названий (а их много!), упоминаемых в источниках по Куликовской битве, на территории Москвы. Например, по их мнению, речка в Москве, известная нам сегодня под именем Напрудная, и есть та самая речка “Напрѧда”.
Можно сказать, что и версия Нечаева и версия Фоменко или одинаково достоверны или одинаково недостоверны: и в том и в другом случае оригинальное название реки не соответствует ее современному названию. Однако, на мой взгляд, противоречий в версии Нечаева больше, хотя бы потому, что раскопки не дали никаких значимых результатов. Однако, историческое научное сообщество решило не воспринимать команду Фоменко всерьез и даже слова его версии на суде истории не давать. Например, русскоязычные страницы Wikipedia, посвященные Куликовой битве и Куликовому полю не упоминают Новую Хронологию вообще.
Сейчас речь не о том, где на самом деле находится Куликово поле. Меня, да и вас, уважаемые читатели, это напрямую никак не касается, и установление истины жизнь нашу никак не изменит. Однако, задумайтесь, в развитом ли обществе мы живем, если альтернативные версии исторических событий не имеют права на голос в “суде”? И дело даже не в государстве, не в Wikipedia, не в учебниках истории. Дело в нас с вами. Способны ли мы беспристрастно анализировать работы историков, критиковать их, спорить с ними, опровергать их версии, но при этом уважать их? Уважать их так, как справедливый судья в равной мере уважает как прокурора, так и адвоката. Или в нашей голове есть место только для одного “канонического” Куликова поля?
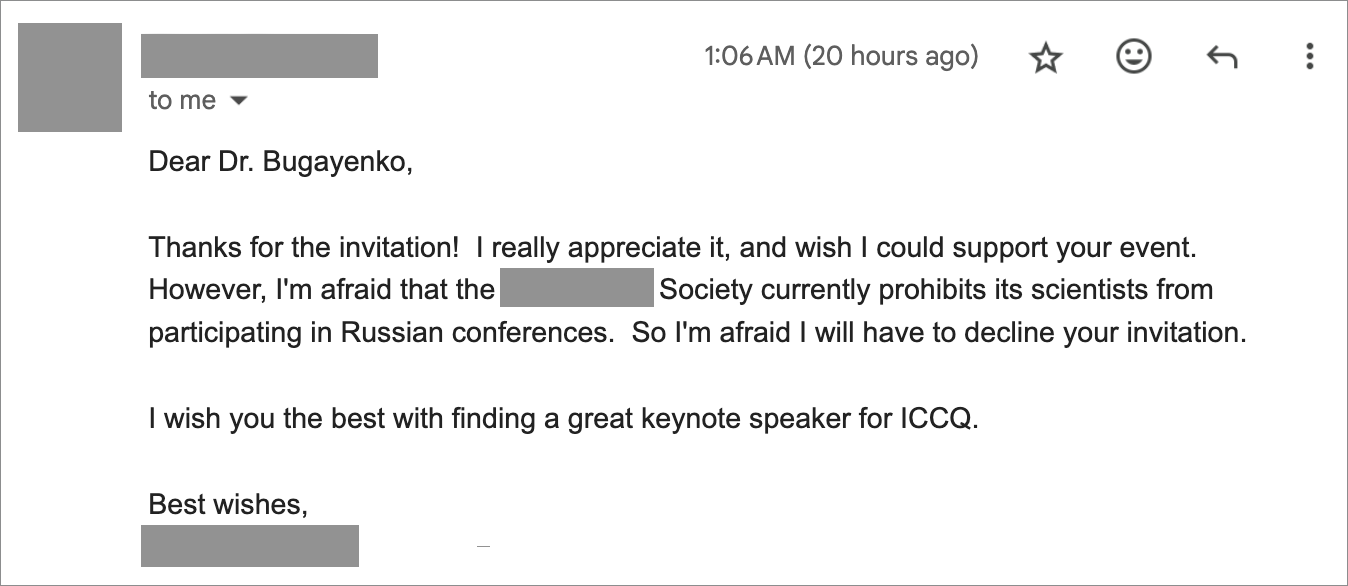
Позвольте закончить свою мысль одной поучительной историей. Несколько месяцев назад мне повезло иметь возможность пообщаться с Анатолием Тимофеевичем Фоменко и Глебом Владимировичем Носовским на своем YouTube канале, в формате интервью. Мы говорили в основном о Новой Хронологии, о их взгляде на историю и о сложностях, с которыми сталкиваются авторы альтернативных взглядов на нее. Через некоторое время после публикации обоих видео роликов я пригласил на интервью другого ученого, доктора технических наук, и получил отказ. Привожу его полностью:

Мне было стыдно читать это письмо. Стыдно за наших ученых.
У меня все.
]]>